How Brand Radar measures AI search visibility — the methodology
Brand Radar measures citation rate and share of voice across ChatGPT, AIO, Gemini, Claude, Perplexity. The 5-stage pipeline, explained.
Brand Radar is Citare's measurement instrument for AI search visibility. Each weekly run dispatches a tightly-curated set of queries across the five AI search platforms — ChatGPT, Google AI Overview, Gemini, Claude, Perplexity — captures the full response on every platform, parses each response for brand mentions and citation positions, and returns four numbers per platform plus a competitor delta: surface rate, top-recommended rate, average citation position, and share of voice.
This guide explains the five-stage pipeline, the query-mix discipline, and the persona library that produces those numbers — so you can read the output with confidence and reproduce the methodology on any brand.
What Brand Radar actually measures
Brand Radar measures one thing: whether AI search engines surface your brand when a target customer asks a question they would naturally ask.
The instrument reports four numbers per platform, per week:
- Surface rate — the fraction of dispatched cells where your brand appears anywhere in the AI engine's answer body.
- Top-recommended rate — the fraction of cells where your brand is the #1 named option (not just mentioned in a list).
- Average citation position — when your brand is mentioned, the average rank in the answer (1 = first named).
- Share of voice — your brand's total mentions divided by the sum of all brand mentions across all dispatched cells.
These four metrics plus the competitor delta table (same four numbers, for each tracked competitor) are the entire output. There is no proprietary "AI visibility score" that bundles them into one opaque number — the four metrics are independent signals and a falling top-recommended rate at flat surface rate is a different problem than a falling surface rate, and the playbook to fix each is different.
Why measure across 5 platforms, not just ChatGPT
The five major AI search platforms each draw from a different underlying index. ChatGPT search and Microsoft Copilot ground in the Bing index. Claude's web search grounds in Brave. Google AI Overview, AI Mode, and Gemini all ground in the Google index via retrieval-augmented generation. Perplexity maintains its own index built from a hybrid of public-web crawl and licensed data.
This is the four-index reality — and it means monitoring one platform doesn't tell you anything reliable about the others. We have run identical queries through all five platforms in week after week of audit data. The surface-rate variance across platforms on the same query routinely lands at 40 percentage points or more. A brand can sit at 100% surface on ChatGPT and 50% on Claude in the same week, and the root cause is almost always an upstream index difference, not a content quality difference.
Brand Radar dispatches every query against all five platforms in the same week because the only way to detect platform-specific gaps is to measure them in parallel.
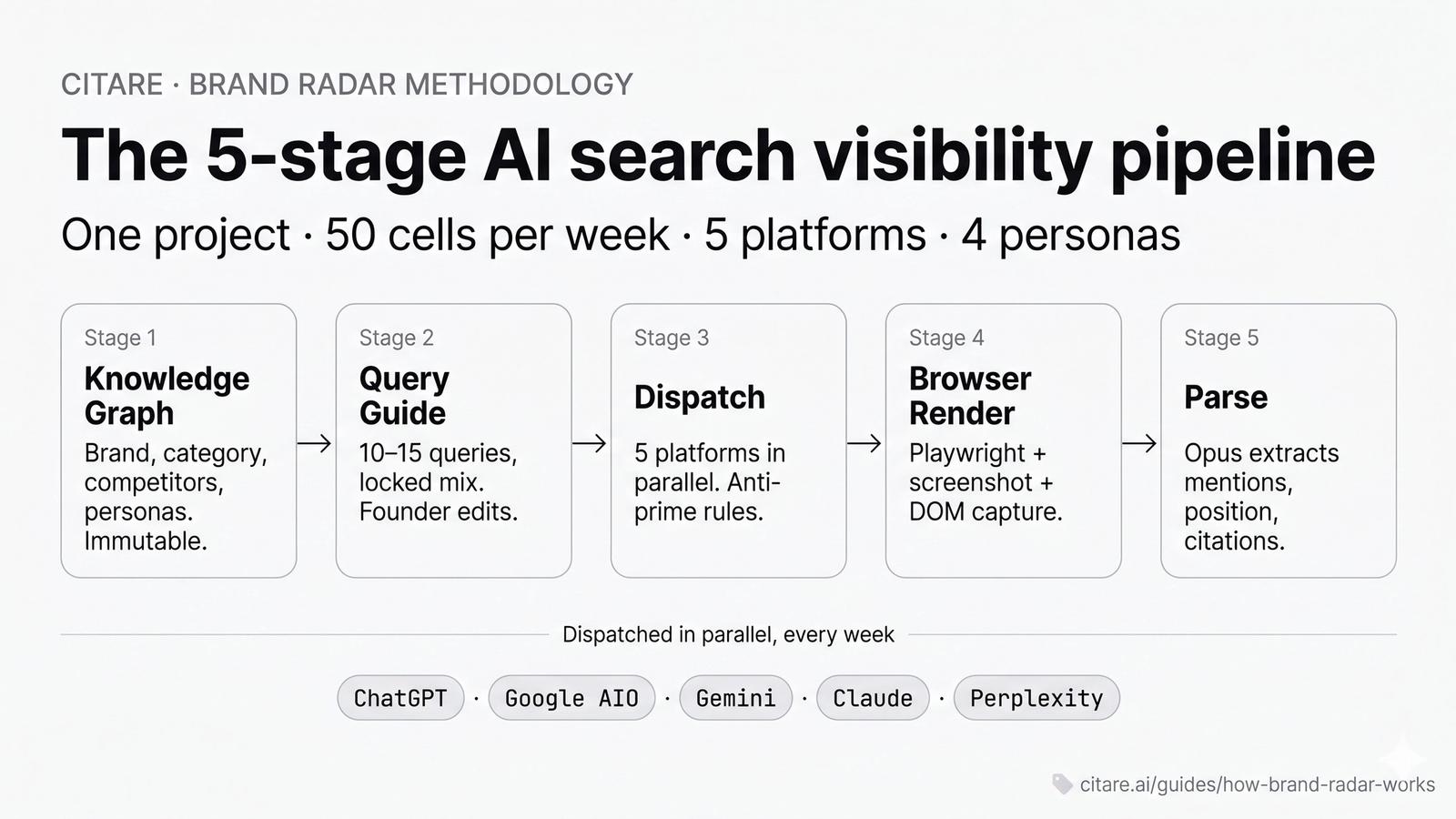
The 5-stage pipeline
┌──────────────────────────────────────────────────────────────────────┐
│ Stage 1 Knowledge Graph build (one-time, immutable) │
│ Stage 2 Query Guide draft + founder edit (per project) │
│ Stage 3 Dispatch — Sonnet generates per-platform prompt context │
│ Stage 4 Browser render — Playwright + Browser Rendering captures │
│ Stage 5 Parse — Opus extracts mentions, positions, citations │
└──────────────────────────────────────────────────────────────────────┘Each stage has a specific job. None can be skipped.
Stage 1 — Knowledge graph (KG)
The first time a brand enters Brand Radar, we build a knowledge graph of the brand from its homepage + about page + product pages + the brand's own llms.txt if present. The KG captures the brand's category, named products, named personas (the brand's stated target customer), named competitors, named differentiators, and named jobs-to-be-done. It is immutable by design — once written, it is not editable from the dashboard, and the rebuild cooldown is 30 days.
Why immutable? Because the KG is the input to the Query Guide, and a brand that can rewrite its own KG can game the queries it gets measured against. The KG is the audit's grounding evidence; if it drifts, the longitudinal trend becomes unreadable.
Stage 2 — Query Guide
The Query Guide is a per-project artifact, drafted by Sonnet from the KG, and then founder-edited. The Guide locks the query mix for the project — typically 10 to 15 queries spread across 3 to 4 personas, with the mix ratio held constant.
The standard mix ratio:
- 30% category queries — "best [category] for [persona constraint]." Anti-prime — must not name the brand in the query.
- 25% comparison queries — "[brand] vs [named competitor]." The brand is explicitly named.
- 20% branded queries — "[brand] review," "is [brand] worth it," "[brand] for [JTBD]." The brand is named.
- 25% job-to-be-done queries — "how do I [JTBD]" or "what tool should I use to [JTBD]." Anti-prime — must not name the brand.
The anti-prime rule on category + JTBD queries is the whole point of the audit. If you let the brand name slip into the query, every model will return the brand at position #1, and you have measured nothing.
The Guide also locks personas — typically pulled from Citare's reusable persona library (knowledge-worker, technical-PM, startup-founder, ops-lead, India-SMB, India-D2C-founder, etc.) plus brand-specific personas the founder writes during the edit phase.
Stage 3 — Dispatch
Each query × persona × platform combination is one cell. A standard run with 10 queries × 5 platforms = 50 cells. With 4 personas distributed across queries, the run hits roughly the same 50-cell volume per week.
For each cell, Sonnet generates the platform-specific request context — for ChatGPT search, that means a clean user turn with persona framing in a system preamble. For AIO, it's a Google query string. For Perplexity, it's a Perplexity URL with the appropriate Pro/standard mode. For Claude, it's a Claude.ai web-search-enabled conversation start. For Gemini, it's a gemini.google.com query.
The dispatch layer is platform-specific because each platform has a different request envelope — and getting any envelope wrong silently degrades the response (Perplexity Pro returns different content than standard; Claude with no web access returns hallucinations; Gemini with thinking mode silently consumes the output budget). Every envelope is tested as part of platform onboarding and locked.
Stage 4 — Browser render + capture
Most platforms don't have first-party APIs that return the full answer body with citations attached. Brand Radar therefore captures the rendered DOM via Playwright (for ChatGPT, Claude, Gemini, Perplexity) and screenshots-plus-Haiku-vision (for Google AI Overview, where the AIO panel doesn't always materialize in the DOM consistently and the screenshot is the only reliable source).
Captures preserve:
- The full answer text body
- Every citation URL (where the platform exposes it — AIO, Perplexity, and ChatGPT search expose citations; Claude and Gemini are inconsistent)
- The platform's own ordering of recommendations in the answer
- A timestamp and the run's UUID for reproducibility
Raw captures are preserved for 90 days so any cell can be re-parsed if the parser logic changes.
Stage 5 — Parse + score
Opus parses each captured response and emits a structured envelope per cell:
{
"platform": "claude",
"query_id": "Q03",
"persona": "startup-founder",
"brand_mentioned": true,
"brand_position": 1,
"is_top_recommendation": true,
"competitors_mentioned": ["Linear", "Asana"],
"citation_urls": [],
"answer_snippet": "...",
"mentions_<custom_field>": false
}The custom-field slot (e.g. mentions_mcp, mentions_white_label, mentions_open_source) lets the audit measure a specific positioning attribute beyond raw mention rate. In the recently-published Notion audit, the mentions_mcp field measured how often AI engines organically surfaced Notion's Model Context Protocol integration — the answer was 15% on non-branded queries, against 100% when the query named MCP. That asymmetry was the headline finding.
The parsed envelopes aggregate into the four metrics + the competitor delta table, plus any conditional findings the custom field unlocks.
Query mix discipline — the rule we never break
The single most common failure mode in DIY AI search monitoring is loose query mix. Specifically:
- Letting the brand name appear in queries that are supposed to be anti-prime. Every model will recommend a brand named in the query at position #1, and every audit will then "prove" the brand has 100% surface rate.
- Drifting the query mix between weeks. If the week-1 mix is 5 branded + 5 JTBD and the week-2 mix is 7 category + 3 comparison, the surface rate delta between weeks is meaningless.
- Asking only the questions the brand wants answered. If every query is phrased the way the brand's marketing site phrases its category, every AIO response will surface the brand because the brand's site is ranking for that phrasing.
Brand Radar's Query Guide locks the mix at draft time, and the founder edit is the only edit channel. Once a run executes, the Guide is frozen for that week. Weeks 2, 3, 4 use the same Guide, edited only if the founder explicitly versions it (which the dashboard tracks).
Persona library — why one persona is never enough
A standard project runs against 3 to 4 personas because the same query phrased from a different persona returns different brands. "Best knowledge base for a 5-person startup" returns different brands than "best knowledge base for a Fortune 500 IT team," even though both queries are technically about the same category.
Citare's persona library is documented in the Citare V2 Brand Radar ADR set. The library is cross-brand reusable — the same startup-founder persona shape is used in every project, with brand-variable counts (a SaaS brand might run 4 personas including 2 brand-specific; a D2C brand might run 3 personas including one regional). Reusable personas mean the methodology is comparable across brands published in /audits — when we say "Notion's surface rate is 85% and Linear's is 78%" the comparison is grounded in identical persona scaffolding.
What the output looks like — a real example
A standard Brand Radar dispatch produces a per-week report containing the four metrics, the competitor delta table, the per-cell breakdown, and the parsed envelopes. From the published Notion audit, one platform's slice:
- ChatGPT — Surface: 15/15 (100%) · Top-rec: 10/15 (67%) · Avg position: 1.40
- Gemini — Surface: 14/15 (93%) · Top-rec: 7/15 (47%) · Avg position: 1.64
- Google AIO — Surface: 13/15 (87%) · Top-rec: 8/15 (53%) · Avg position: 1.45
- Perplexity — Surface: 12/15 (80%) · Top-rec: 7/15 (47%) · Avg position: 1.33
- Claude — Surface: 10/15 (67%) · Top-rec: 8/15 (53%) · Avg position: 1.20
Two patterns immediately visible: ChatGPT is the strongest platform for Notion (100% surface), and Claude is the weakest (67%). Claude's average position when present is the best (1.20) — when Claude does name Notion, it ranks Notion at the top. The action this unlocks is different per platform: closing the Claude surface gap requires getting Claude's underlying search grounding to index more Notion-favorable comparison content; the AIO and Gemini gaps require structured-data work; the Perplexity gap is about specific page indexing.
These platform-level deltas are not visible if you measure only one platform. The pipeline exists to surface them.
How Brand Radar differs from single-platform monitoring
Several point tools measure one platform — typically ChatGPT or AIO — and report a citation count. The category-level differences:
- Single-platform tools answer "where do I rank in ChatGPT this week." Brand Radar answers "where do I rank in all five AI surfaces this week, and which gaps are platform-specific vs systemic."
- Single-platform tools don't enforce anti-prime query discipline. If a tool lets you type "best SEO tool 2026 — is Citare worth it" as one query, you're not measuring what you think you're measuring.
- Single-platform tools rarely expose the parsed envelope. Brand Radar preserves raw captures + parsed JSON for 90 days; an audit's findings are reproducible against the artifacts.
- Single-platform tools don't track competitor delta. Knowing you surfaced on 60% of queries this week means nothing without knowing your top-3 competitors surfaced on 75%.
How often to run — and how to read the trend
Tier-locked cadences (from the pricing page):
- Free — one project, 50-cell weekly run.
- Pulse $35 / ₹2,999 — one project, 50-cell weekly run, weekly trend dashboard.
- Pro $119 / ₹9,999 — five projects, 75-cell weekly runs, custom-field configuration.
- Agency $299 / ₹24,999 — fifteen projects, 100-cell weekly runs, white-label exports.
- Enterprise — custom cell counts, SSO, custom retention.
Weekly is the right cadence. Less frequently than weekly and your trend can't catch a platform behavior change (we have observed AIO regenerate its panel composition mid-week; Claude has shipped two web-search backend updates that shifted citation patterns within 14 days). More frequently than weekly produces noise — model temperature variance contributes ~3% surface-rate jitter that smooths out at weekly aggregation but dominates daily readings.
Reading the trend: any single metric moving 5 percentage points week-over-week is signal worth investigating. Any metric flat for 4 consecutive weeks is signal that something in the upstream content layer needs to change.
Frequently asked
What's the difference between citation rate and share of voice? Citation rate is the fraction of dispatched cells where your brand is named. Share of voice is your brand's total mentions divided by the total mentions of all brands across all cells. A brand with 80% citation rate and 30% share of voice is named in most answers but always alongside many competitors; a brand with 50% citation rate and 50% share of voice is named in fewer answers but dominates when named. The deeper definitional break is in our citation rate glossary entry and share of voice glossary entry.
Can I run Brand Radar on a competitor without their permission? Yes. The methodology is observational — we dispatch the same kind of queries any prospective customer might ask. Citare's published /audits cluster runs against famous brands (Notion is published; Linear, Vercel, Cursor are queued) without prior permission, with methodology transparency as the ethics floor: every audit is reproducible against the raw envelopes we preserve.
How is Brand Radar different from Google Search Console? GSC reports classic blue-link search performance — clicks, impressions, average position on the 10-blue-links SERP. Brand Radar reports AI-generated-answer performance — whether your brand appears in the synthesized text the AI engine returns. Both matter; they measure different surfaces of the same underlying index for Google but completely separate systems for ChatGPT, Claude, and Perplexity.
What query volume produces useful data? A 50-cell weekly run (10 queries × 5 platforms) produces statistically meaningful surface-rate readings for a brand with established category presence. Brands with no public footprint may need 75-100 cells to differentiate noise from signal. The configurable per-tier cell count exists so customers can dial up for niche categories.
Can I add custom metrics like "mentions our latest feature"? Yes on Pro tier and above. The custom-field slot in the parsed envelope (mentions_<name>) accepts a boolean test defined by you. The Notion audit's mentions_mcp field is one example — the test was "does this response describe Notion's Model Context Protocol integration on its own initiative, without the user prompting for MCP." The conditional matrix in the audit shows how that field unlocked Finding 9, the headline of the entire piece.
Ready to baseline your own brand?
Free forever tier covers one project with a 50-cell weekly run — the same shape we publish the famous-name audits with. Onboarding takes ~10 minutes: enter your domain, edit the Sonnet-drafted Query Guide, kick the first run. Results in 90 minutes.
→ Learn the difference between citation rate and share of voice
→ Read the published Notion audit to see the methodology applied end-to-end
→ See the live Brand Radar product page for tier comparison