How to Measure AI Search Visibility: A Complete Framework
A complete framework for measuring AI search visibility — query design, persona dispatch, citation parsing, surface rate, competitor benchmarking.
A SaaS founder we worked with last quarter described his AI search strategy this way: "We saw our brand mentioned by ChatGPT once. So we figured we were doing fine."
A single screenshot. A category-wide strategic decision. Three months later they had spent significant content and engineering effort on the wrong platform — they were strong on ChatGPT (which had cited them once, by chance) and invisible on Perplexity, where their actual buyer audience was concentrated.
This is the cost of measurement-by-anecdote. AI search visibility cannot be inferred from screenshots, hunches, or single-platform spot checks. It has to be measured systematically, across all four major platforms, with persona-anchored query dispatch and competitor benchmarking. Anything less produces decisions that look directionally correct and are structurally wrong.
This guide is the complete framework for AI search visibility measurement: what to measure, how to measure it, how often, and how the resulting data should drive optimization decisions. If you have not yet read the foundational guides, What is Generative Engine Optimization (GEO)?, GEO vs SEO, and The Four AI Search Platforms Explained provide the conceptual backdrop. This guide is the operating manual.
What "AI Search Visibility" Actually Means — Three Distinct Layers
The phrase "AI search visibility" gets used loosely. For measurement purposes, it has to be decomposed into three distinct layers, each of which fails for different reasons and requires its own measurement.
Layer 1: Indexed
Does the platform's crawler have your content?
This is the prerequisite for everything else. If GPTBot has not crawled your site, your content cannot be considered for inclusion in ChatGPT's training data. If PerplexityBot is blocked, Perplexity cannot cite you. If Bingbot has thin coverage of your domain, ChatGPT's web search will not find you.
Indexed-layer measurement is unglamorous: server log analysis for AI crawler user agents, crawl frequency monitoring, sitemap coverage verification in Bing Webmaster Tools, robots.txt audits.
Layer 2: Cited
Does the platform reference your brand in its answers?
This is the layer most people mean when they say "AI search visibility." It is also the layer where surface rate is computed. Cited-layer measurement requires real query dispatch, persona context, response parsing, and brand-mention detection.
A brand can be fully indexed (Layer 1) and rarely cited (Layer 2). Crawl access is necessary but not sufficient for citation.
Layer 3: Routable
Does the citation drive traffic, perception change, or buyer action?
This is the hardest to measure and is where most measurement programs stop. Cited mentions drive different outcomes depending on context: a Perplexity citation with a clickable source link drives referral traffic; a Gemini comparison mention shapes buyer perception without producing a click; a ChatGPT recommendation in a long conversation may influence a decision weeks later that never traces back to AI search at all.
Layer 3 measurement combines citation data with referral traffic analytics, brand-search trend analysis, and qualitative buyer feedback. It is the layer where attribution is most contested.
Why this layering matters: A measurement program that conflates these layers makes wrong decisions. "We're not visible on AI" can mean three different problems with three different fixes. Treating them as one number leads to spending optimization budget on the wrong layer.
Why Traditional Measurement Tools Break for AI Search
Every major SEO measurement platform — Google Search Console, Ahrefs, Semrush, BrightEdge, Sistrix, Moz — was built around Google rank tracking. Their architecture is:
- Periodically scrape Google SERPs for your tracked keywords
- Record the rank position of your URLs
- Aggregate movement over time
- Surface alerts when ranks change
This architecture has zero overlap with AI search measurement. AI platforms do not produce ranked URL lists. They produce generated answers. The unit of measurement is not "did our URL move from position 4 to position 3" — it is "was our brand cited at all, in what context, for which persona, on which platform."
Specifically, traditional SEO platforms cannot:
- Dispatch real queries against ChatGPT, Gemini, or Perplexity (these have no public ranking API)
- Run queries with persona context (no concept of personas in SEO architecture)
- Parse generated answer text for brand mentions (no NLP layer)
- Capture citation context — recommended vs compared vs mentioned (no schema for this)
- Compute surface rate (no metric for it; rank position is the only metric)
- Benchmark per-platform (one index assumed)
A few SEO platforms have begun adding limited Google AI Overview tracking, but coverage of ChatGPT, Gemini, and Perplexity remains thin or non-existent in the legacy stack. A real AI search monitoring tool is structurally a different product, not a feature add-on. The data model is different. The dispatch infrastructure is different. The metrics are different. Treating an SEO suite as your GEO measurement layer is a category error.
The Five Pillars of AI Search Measurement
Every serious AI search measurement framework rests on five components. Skip any one of them and your measurement produces noise instead of signal.
- Query design — what queries you dispatch
- Persona anchoring — under what user context the queries are sent
- Platform matrix — which AI platforms receive each dispatch
- Citation parsing — how you extract brand mentions from generated text
- Competitor benchmarking — how you compare your performance to alternatives
The next sections expand each of these into operating practice.
Query Design: What to Actually Ask
The biggest mistake in AI search measurement is using your existing SEO keyword list as your query set. SEO keywords are short-form, high-volume, structurally optimized for Google rank tracking. AI search queries are conversational, intent-rich, and often longer — they reflect how people actually talk to assistants.
A useful AI query set spans four query types:
Category queries (top of funnel)
The buyer is exploring the category, not yet evaluating brands.
Example for B2B SaaS analytics: "What are the best customer analytics tools for SaaS companies?"
These queries have the highest volume and are where category leaders show up. If you are absent from category queries, you are not yet in the consideration set.
Comparison queries (mid-funnel)
The buyer is evaluating two or more named alternatives.
Example: "Is Mixpanel or Amplitude better for product-led SaaS?"
These queries reveal how AI platforms position you relative to specific competitors. They are the most actionable category for content strategy because losing a comparison query points to a missing comparison page or weak structured data.
Branded queries (bottom of funnel)
The buyer has already heard of your brand and is evaluating it.
Example: "Is [Brand] worth the price?" or "Does [Brand] support [feature]?"
Branded queries reveal what AI platforms know and say about you specifically. Negative or outdated information surfacing on branded queries is a high-priority fix because it directly affects buyer decision-making at the point of conversion.
Recommendation queries
The buyer is asking for a specific recommendation.
Example: "Recommend a CRM for a 50-person fintech in India"
These are highest-conversion queries. They surface in different forms on each platform — Gemini surfaces them most directly, Perplexity in research-style aggregations, ChatGPT in conversational suggestion form, AIO in concise list form.
Sample size
For stable measurement, plan on 50–150 queries per persona, distributed across the four query types. With four query types this means 12–37 queries per type per persona. Smaller query sets produce noisier surface rates with high week-over-week variance; larger query sets produce stable trend lines but consume more dispatch budget.
Refresh cadence
Query sets should be refreshed quarterly. New queries get added as the category evolves — new product features, new competitor entrants, new use cases. Old queries should not be removed mid-cycle (it breaks trend continuity), but should be retired in scheduled refresh cycles.
Persona-Anchored Dispatch: Why "Naked" Queries Lie
The single most common methodological error in early AI search measurement is dispatching queries without persona context. The result: every query produces a single response, and that response is what the platform's default user model returns. This dramatically under-represents the variance real users experience.
The persona context blob
A persona is a 50–80 word context block that primes the AI assistant with information about the user asking the query. A good persona blob includes:
- Role and seniority ("CMO at a 50-person B2B SaaS company")
- Geography ("based in Bangalore, India")
- Industry / use case ("targeting mid-market enterprise buyers in fintech")
- Sophistication level ("comfortable with technical product discussions")
- Known constraints ("evaluating tools that integrate with HubSpot")
Persona blobs are prefixed to each query in the dispatch. The same query produces different responses depending on persona, often surfacing different brands, different comparison sets, and different feature emphases.
How many personas per category
For a stable measurement program: 3–5 personas per category. Fewer personas miss the variance; more personas dilute statistical signal across each persona's slice without adding insight.
For B2B SaaS, persona variation along buyer-role lines is most useful (CEO, CMO, head of engineering, end-user, agency-buyer). For D2C consumer brands, persona variation along buyer-context lines is most useful (price-sensitive shopper, premium shopper, gift buyer, repeat buyer). For local services, geography is the dominant variable.
Why this matters operationally
In one B2B audit we ran, a brand showed a 38% surface rate when measured under one persona (CTO) and a 4% surface rate under another persona (CMO) — same category, same platforms, same queries, different persona. Without persona anchoring, the measurement program would have averaged these (~21%) and missed the structural insight: the brand's content speaks to technical buyers and is invisible to economic buyers. Average obscures actionable variance.
The Platform Matrix: The Math
Your dispatch volume is a multiplication problem.
- Platforms — Variable: P · Typical value: 4 (AIO, ChatGPT, Gemini, Perplexity)
- Personas — Variable: N · Typical value: 3–5
- Queries — Variable: M · Typical value: 50–150 per persona
- Total dispatches per cycle — Variable: P × N × M · Typical value: 600–3,000
For a typical B2B SaaS measurement program: 4 × 5 × 100 = 2,000 dispatches per cycle. For a D2C consumer brand with 3 personas and 75 queries: 4 × 3 × 75 = 900 dispatches per cycle.
This is not feasibly manual. A human running 2,000 queries through chat interfaces, copying responses, and tagging brand mentions takes weeks per cycle and produces inconsistent data. Either you automate this end-to-end or you accept that your measurement is sparse, noisy, and out of date.
This is also where the "build vs buy" decision shows up — most teams that try to build their own dispatch infrastructure underestimate the engineering complexity (per-platform parsers, geo-seeding, anti-bot mitigation, citation context extraction, time-series storage) and converge on either a vendor or an internal team with months of dedicated build time.
Citation Parsing: Per-Platform Output Formats
Each AI platform produces a different output format. Your parser has to handle each one.
Google AI Overview
AIO appears as an HTML block at the top of the Google SERP. It contains the synthesized answer plus a list of source pills with linkable URLs. Capture requires loading the SERP in a real browser (Playwright, Puppeteer) — Google's APIs do not return AIO content. Geo-seeding (setting the gl= parameter or geo-locating the headless browser) is required for accurate measurement of city-level queries.
Parse output: extract the AIO container, parse linked source pills, OCR or vision-extract the text body. Citare's pipeline uses Playwright for capture and a vision-parse step (Claude Haiku running on the rendered screenshot) to extract the citation set robustly across Google UI changes.
ChatGPT
ChatGPT's output is conversational text, optionally with inline source links if web search is enabled. Capture requires either the official API (which has rate limits and may not surface the same retrieval behavior as the consumer app) or a browser-driven session. The captured response is plain text plus optional source links.
Parse output: extract brand mentions via NLP (entity recognition tuned to your tracked competitor and brand list), classify each mention's context, capture any inline source URLs for routable-layer attribution.
Gemini
Gemini's output is conversational text, sometimes attributed to specific sources. Like ChatGPT, capture is via API or browser-driven session. Gemini's response format includes side-cards, comparison tables, and standalone source attributions in some answer types.
Parse output: extract brand mentions, distinguish between primary answer brands and comparison-card brands (different citation contexts), capture attributions where present.
Perplexity
Perplexity is the most directly parseable. Each answer comes with a numbered citation list. Source URLs are explicit. Parse output: extract the numbered citation list, attribute each mention to its citation, capture position in the citation list (position 1 vs position 8 matters).
Edge cases
- Pronoun resolution. AI platforms sometimes reference your brand by pronoun ("it offers strong free-tier features") after first mention. Naive parsers miss the second-sentence attribution. Better parsers track conversational context.
- Brand-name collisions. If your brand name is also a common noun ("Amazon" the company vs "Amazon" the river, "Apple" the company vs "apple" the fruit), parsers need disambiguation logic.
- Misspellings and aliases. Buyers frequently mis-type or use abbreviations. Your parser should normalize aliases ("Notion" vs "Notion AI" vs "@notion") to a single brand entity.
These edge cases are why "spin up a Python script to grep for brand names" produces unusable measurement data. Real citation parsing is a non-trivial engineering effort.
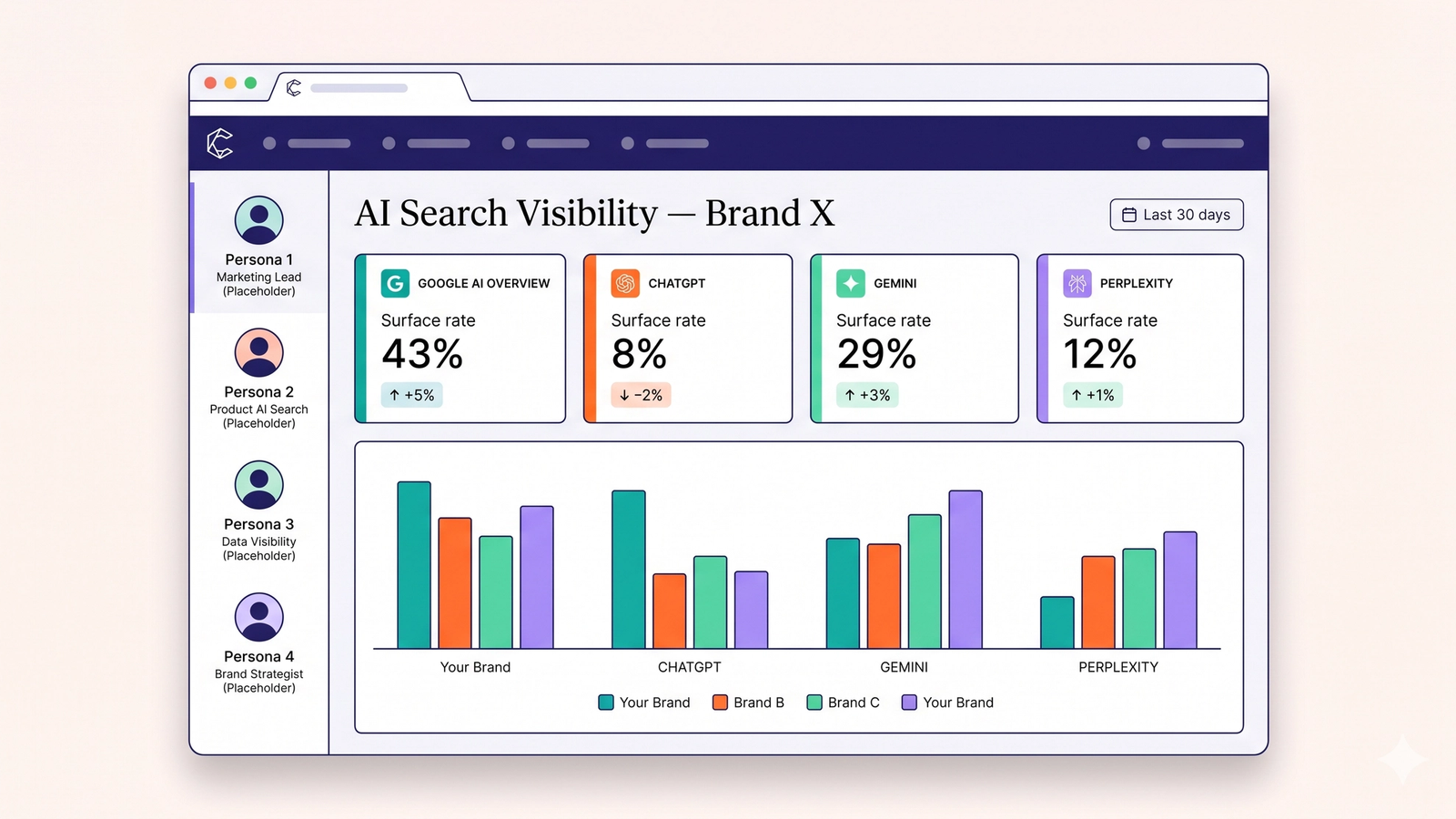
Surface Rate: The Primary Metric
Surface rate is the share of dispatches in which your brand is cited.
Surface rate = (dispatches where brand is mentioned) / (total dispatches) × 100Per-platform breakdown
The single most important refinement: report surface rate per platform, never as an aggregate.
- AIO — Dispatches: 500 · Mentions: 215 · Surface rate: 43%
- ChatGPT — Dispatches: 500 · Mentions: 40 · Surface rate: 8%
- Gemini — Dispatches: 500 · Mentions: 145 · Surface rate: 29%
- Perplexity — Dispatches: 500 · Mentions: 60 · Surface rate: 12%
Aggregate surface rate (here: 460/2000 = 23%) is the worst metric because it hides the per-platform asymmetry that determines optimization priority. The brand above has a Bing/ChatGPT problem and a Perplexity content-depth problem, masked by the aggregate average.
Per-persona breakdown
For each platform, also break down by persona. This reveals whether your visibility is even across audience segments or concentrated in one buyer profile.
Per-query-type breakdown
Surface rate by query type (category / comparison / branded / recommendation) reveals funnel weakness. A brand strong on branded queries and weak on category queries has a top-of-funnel discovery problem. A brand strong on recommendation queries and weak on comparison queries has a positioning problem in mid-funnel.
These three breakdowns — platform, persona, query type — are the actionable cuts.
Citation Context: Beyond Mention / No-Mention
Surface rate treats citations as binary. In B2B and considered-purchase categories, the context of the citation matters more than the count.
Citation context taxonomy
- Recommended — the brand is offered as the answer to a recommendation query
- Compared favorably — in a comparison, the brand wins on the primary criterion
- Compared neutrally — in a comparison, the brand is presented but no preference is indicated
- Compared negatively — the brand is positioned as worse than an alternative
- Mentioned as alternative — listed in an "other options include..." clause
- Mentioned as deprecated — the brand is described as outdated or no longer leading
- Passing reference — brand named without contextual evaluation
- Quoted as authority — the brand is cited as a source for a fact (most common in Perplexity, valuable for routable-layer)
Why context matters
A brand cited 100 times in "passing reference" mode produces less buyer impact than a brand cited 30 times in "recommended" mode. Citation count is a vanity metric without context.
For B2B audits, context attribution is mandatory. For D2C consumer brand audits where most citations are top-of-funnel discovery, context matters less but should still be captured because "compared negatively" mentions are reputational risks worth flagging.
Competitor Benchmarking: Your Surface Rate Alone Is Meaningless
A 12% surface rate could be excellent or catastrophic depending on whether your closest competitor is at 5% or 60%. Without competitor data, the number is uninterpretable.
How to set up competitor benchmarking
- Identify 3–5 named competitors in your category. Include the obvious leaders, the obvious peers, and one rising challenger if relevant.
- Run the identical query set, persona set, and platform matrix for each competitor.
- Compute surface rate per competitor with the same methodology.
- Visualize the comparison per platform and per query type.
What to do with the data
Competitor benchmarking surfaces three actionable patterns:
- Structural gaps — a competitor consistently winning ChatGPT queries while you win AIO queries reveals a Bing-coverage advantage you can replicate
- Query-level losses — specific queries where you are absent and a specific competitor is dominant indicate content gaps where you should publish to compete
- Trend divergence — your surface rate is steady but a competitor's is rising fast indicates they are running an active GEO program and you are losing share
Without competitor data, you can see your number move but you cannot interpret whether the movement is good (you are improving) or bad (the category is improving and you are falling behind).
Crawler Health: The Input Layer
Before any of the above measurement makes sense, you need to know whether AI crawlers are actually accessing your site. This is the input layer to everything else, and it is the layer most often broken without anyone noticing.
What to monitor
- GPTBot — OpenAI's crawler for training data
- ClaudeBot — Anthropic's crawler
- PerplexityBot — Perplexity's crawler
- Google-Extended — controls Google's use of your content for AI training (separate from Googlebot for organic search)
- Bingbot — powers ChatGPT's web search
- Anthropic-AI / CCBot / others — secondary crawlers worth tracking
How to monitor
The most reliable method is server-side log analysis. Grep your access logs for known AI bot user agents over a rolling time window (last 7 days, last 30 days), aggregate by bot, and compute crawl frequency per priority page. Many brands discover they have one crawler accessing five pages a week and another never visiting at all.
llms.txt as a signaling mechanism
A growing standard is the /llms.txt file at site root, which provides AI systems with a curated summary of your site's purpose, key topics, and authoritative pages. Whether AI platforms actually consume llms.txt at present is debated — adoption is uneven and the protocol is informal — but publishing one costs nothing and serves as a forward-compatible signal as adoption grows.
When crawler access is broken
If GPTBot is blocked in robots.txt, your content cannot enter ChatGPT's training data. If PerplexityBot is blocked, Perplexity cannot cite you. Crawler-level blocks cap your ceiling regardless of how much content optimization you do. This is the fastest, lowest-cost win for most brands starting an AI search visibility program.
(For deeper coverage of crawler access setup, see the planned cluster post on AI Crawler Monitoring and the AI Crawler Access Guide.)
Measurement Cadence: How Often to Run
Cadence should match the rate at which the underlying environment changes.
Quarterly
For brands in slow-moving categories with stable competitive sets and no active GEO program. Quarterly audits catch major shifts and seasonal patterns. Insufficient for brands actively optimizing.
Monthly
For brands running an active GEO content and optimization program. Monthly cadence catches the impact of recent content publishing, structured data improvements, and competitor moves with enough frequency to drive iteration cycles.
Weekly
For brands in fast-moving categories (consumer, news-adjacent, regulatory-affected categories) or during active product launches. Weekly cadence is expensive in dispatch budget but necessary when category dynamics move faster than the AI platforms can re-index.
Real-time / event-driven
For crisis monitoring — PR events, security incidents, competitor major launches. Real-time means triggering an unscheduled audit when an event occurs, not running continuous live monitoring.
Continuous
Some brands now run continuous AI search visibility monitoring — daily snapshot dispatches against a smaller, targeted query set with weekly full-set audits. This is the highest-cost cadence and is justified for SaaS in active growth or for category leaders defending share.
The Measurement → Optimization Loop
Measurement without an action loop is sunk cost. The output of your measurement program should drive specific optimization decisions.
Pattern: Drop on ChatGPT only
If your surface rate drops on ChatGPT specifically while remaining stable on Google AI Overview and Gemini, the issue is almost always Bing-side. Check Bing index coverage in Bing Webmaster Tools, verify Bingbot is allowed and crawling, and audit whether priority pages have been recently re-indexed. ChatGPT's web search lags Bing's index — your fix at Bing translates to ChatGPT after the next crawl cycle.
Pattern: Strong on Perplexity, weak on Gemini
If Perplexity citations are healthy but Gemini citations are sparse, the issue is usually entity-graph weakness. Gemini relies on Google's Knowledge Graph more than the other platforms. Pursue Wikipedia presence (where editorially appropriate), strengthen sameAs links, claim your knowledge panel, and build named-comparison content for your category — Gemini surfaces comparisons aggressively.
Pattern: Persona-specific drops
If overall surface rate is stable but specific personas show declining citation, the issue is content gap by audience segment. The brand has content for some buyer personas and not others. Targeted content production for the under-served persona resolves this.
Pattern: Aggregate drop with no platform-specific cause
If surface rate is dropping across all four platforms uniformly, the issue is usually category-level — either competitors are running aggressive GEO programs that are eroding your share, or category-relevant content is becoming staler. Competitor benchmarking will distinguish these.
Build vs Buy: What an AI Search Monitoring Tool Actually Does
The case for buying instead of building rests on six engineering problems that compound:
- Query orchestration at scale — dispatching 600–3,000 queries per cycle across four platforms with rate limiting, retries, and per-platform quotas
- Persona library and rotation — managing persona blobs, rotating them per dispatch, avoiding contamination across runs
- Platform-specific parsers — handling four different output formats with edge cases (pronoun resolution, alias normalization, citation context)
- Geo-seeded dispatch — serving queries from multiple geographic origins for geo-aware platforms (especially AIO)
- Time-series storage and drift detection — storing dispatch results, computing trends, alerting on meaningful change
- Competitor benchmarking automation — running parallel competitor query sets, computing comparative surface rates
A team can build all of this. We have spoken to several in-house teams that have. The typical timeline is 3–6 months of engineering effort to reach a usable internal tool, with ongoing maintenance for platform UI changes, parser updates, and new platform additions.
For most teams, this is not the highest-leverage use of engineering time. An AI search visibility platform like Citare absorbs the engineering complexity, runs the dispatches, parses the outputs, computes the metrics, and presents the data. The team's job becomes interpretation and action — the part where their domain knowledge is irreplaceable.
This is the structural argument for buying. The build path produces a data pipeline. The buy path produces actionable insights from day one.
Frequently Asked Questions
How many queries do I need for stable measurement?
50–150 queries per persona, distributed across category, comparison, branded, and recommendation query types. Below 50 the surface rate is too noisy week-over-week; above 150 the additional queries do not meaningfully improve signal. Adjust upward only if your category has unusually high query diversity.
How many personas do I need?
3–5 personas per category for B2B; 3–4 for D2C; 1–3 for narrow local services. Fewer than 3 misses persona variance entirely; more than 5 dilutes statistical signal across each persona's slice without adding actionable insight.
Is one-time auditing useful or do I need continuous monitoring?
One-time audits produce a snapshot. They are useful to establish a baseline and identify the highest-leverage initial optimizations. They do not catch drift, do not measure the impact of optimization work, and do not detect competitor moves. For brands actively investing in GEO, monthly cadence is the minimum useful frequency; for category leaders, continuous monitoring is justified.
Do I need to track all four platforms?
For most brands, yes. Each platform has different audience characteristics and different ranking logic, and aggregate AI search measurement misses the asymmetry that determines optimization priority. Single-platform tracking can be defensible for very narrow audiences (Perplexity-only for some technical B2B) but is rare.
What's the difference between surface rate and citation count?
Surface rate is normalized — it is a percentage of dispatches. Citation count is absolute. Surface rate is comparable across query sets, time periods, and competitors. Citation count is not comparable without normalization. Use surface rate as the primary metric.
How do I attribute traffic from AI search citations?
This is Layer 3 measurement and is the hardest. For Perplexity, citation links produce trackable referral traffic — show up as perplexity.ai referrers in Google Analytics. For Google AI Overview, click-throughs from AIO citations produce direct or organic-search-attributed traffic that is hard to disambiguate. ChatGPT and Gemini produce predominantly perception-level impact rather than click-through traffic. Many brands now track aggregate brand-search trend as a proxy for AI-driven mind-share growth.
What does it cost to run a proper measurement program?
The dispatch volume itself is small in API cost — a 2,000-dispatch monthly cycle costs under $100 in raw API spend. The cost is in engineering and operational time: building the dispatch infrastructure, maintaining parsers, designing query sets, interpreting results, and connecting data to action. For most teams, this engineering cost is the actual variable that matters.
Should I include my own brand-search query in the dispatch set?
Yes, as branded queries. They reveal what AI platforms know and say about you specifically. Negative or outdated information surfacing on branded queries is a high-priority fix because it directly affects buyers at the conversion point.
How do I know my measurement parser is accurate?
Periodic spot-check audits. Take a sample of 50 dispatches per platform per cycle and manually verify whether brand mentions were correctly extracted and citation context correctly classified. Aim for >95% accuracy. Below 95%, parser improvements are higher-leverage than additional dispatch volume.
What should I do first if I have never measured AI search visibility?
In order: (1) audit your robots.txt for AI crawler access; (2) run a one-time baseline audit across all four platforms with 50 queries × 3 personas; (3) compare your per-platform surface rates against 2–3 known competitors; (4) identify the largest gap and fix the highest-leverage layer (almost always crawler access or Bing index coverage); (5) re-measure in 30 days.
Stop Guessing — Measure Your Actual Surface Rate
Citare runs the full measurement framework — query design, persona-anchored dispatch, multi-platform capture, citation parsing, surface rate computation, and competitor benchmarking — across Google AI Overview, ChatGPT, Gemini, and Perplexity. You see your actual numbers, your competitor numbers, and the optimization patterns that matter.
Run your free AI visibility audit → [citare.ai/audit]