From Brand Radar findings to a GEO content roadmap — the operating playbook
Brand Radar tells you where you stand in AI search. The operating playbook for turning findings into a 12-week content roadmap.
Brand Radar tells you where your brand stands in AI search. That's necessary, not sufficient. The work is converting those findings into a prioritized content roadmap, executing it for 12 weeks, and measuring whether each investment moved the platforms it was supposed to move.
This guide is the operating playbook. It covers the gap-analysis frame, the prioritization rubric, the content-brief shape that turns a measurement gap into a publishable page, the publication cadence, and the measurement loop that confirms each investment landed.
Every example in this guide is drawn from real Brand Radar runs we've executed in 2026 — anonymized, but the gap patterns and the responses are mechanical, not invented.
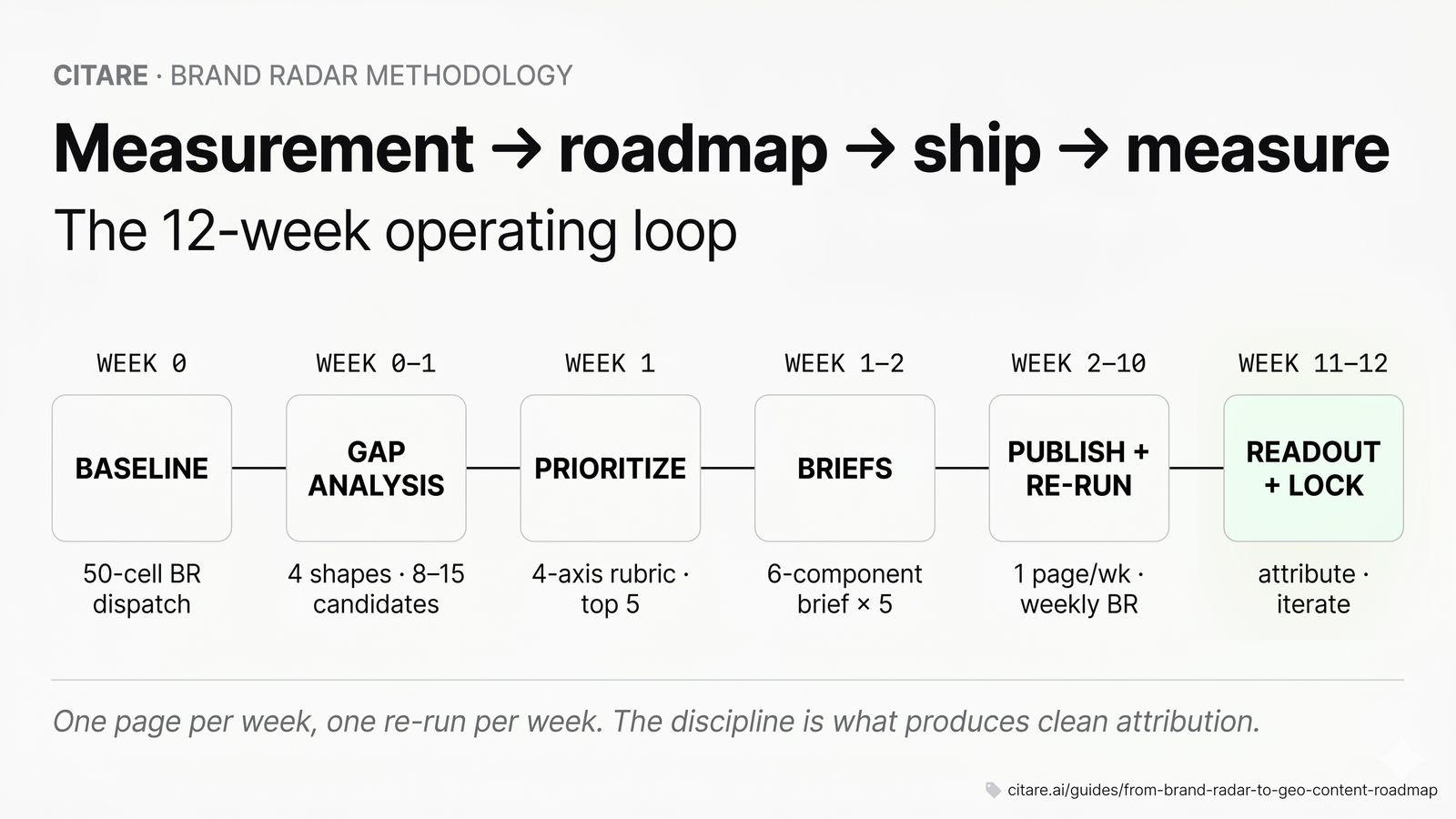
The end-to-end flow
┌──────────────────────────────────────────────────────────────────────┐
│ Week 0 Run baseline Brand Radar dispatch (50 cells × 5 platforms)│
│ Week 0-1 Gap analysis — identify the 5-8 highest-leverage gaps │
│ Week 1 Prioritize gaps using the 4-axis rubric │
│ Week 1-2 Convert top 5 gaps to content briefs │
│ Week 2-10 Publish 1 page per week against each gap, weekly BR run │
│ Week 11 Measure delta on each page's target platform + JTBD │
│ Week 12 Lock the wins, redirect the misses, refresh roadmap │
└──────────────────────────────────────────────────────────────────────┘This is the standard 12-week loop. It is not the only shape — brands with stronger or weaker baselines will run different cadences — but the loop shape is the floor for serious AI search optimization work. Anything shorter than 12 weeks doesn't give the underlying indices time to re-crawl and re-rank.
Step 1 — The gap analysis frame
A Brand Radar baseline produces a per-cell breakdown: which queries, which personas, which platforms surfaced your brand and at what position. Gap analysis turns that breakdown into a small list of high-leverage opportunities.
The four gap shapes worth attention:
Surface gaps — cells where your brand did not appear in the answer body at all. This is the simplest gap. The question is: what page would the AI engine cite instead of yours? Open the cell's raw capture, find the brands and URLs the engine did cite, and read those pages. The pattern is usually obvious — the cited pages use a JTBD phrasing that mirrors the query, while your equivalent page uses category-marketing phrasing.
Position gaps — cells where your brand appeared at position #3-#5 but a clear competitor held position #1. The question is: what does the #1 page have that yours doesn't? Usually it's one of three things: explicit structured comparison content (schema-marked head-to-head), JTBD-phrased H1, or a step-by-step process structure.
Platform-specific gaps — your brand surfaces well on three platforms but consistently low on one or two. The mechanism is almost always an index difference. A brand strong on ChatGPT but weak on Claude usually has third-party-driven visibility (Bing indexes Reddit and aggregators deeply; Brave doesn't); the response is first-party content investment.
Persona-specific gaps — your brand surfaces well for one persona's queries but absent for another. This is the most actionable gap of the four because it directly translates to a content investment: ship a persona-specific landing page targeting the JTBD phrasings the absent persona's queries surfaced.
A clean baseline produces 8-15 gap candidates across the four shapes. The prioritization rubric narrows that to 5 to invest in.
Step 2 — The 4-axis prioritization rubric
Not every gap is worth closing. The four axes:
- **Search volume of the underlying query** — What to score: Use DataForSEO or your existing keyword research to estimate monthly search volume on the cell's query phrasing · Why it matters: A gap on a high-volume query is worth more than the same gap on a low-volume query
- **Competitive density in the answer** — What to score: Count distinct brands named in the cited cell's response · Why it matters: A 3-brand answer is easier to lead than a 10-brand answer
- **Mechanism clarity** — What to score: Score 1-5: how confident are you that you understand why the gap exists? · Why it matters: Closing a gap you don't understand is gambling
- **Time-to-effect** — What to score: Score 1-5: how quickly will the underlying index refresh and reflect new content? · Why it matters: ChatGPT/Bing refresh in days; Claude/Brave in weeks
The simple aggregate: multiply (volume) × (mechanism clarity) × (time-to-effect) ÷ (competitive density). Rank-order the gaps. Take the top 5.
In a recent customer roadmap we built, the top-5 gaps that emerged from this scoring were all platform-specific or persona-specific — none of the high-volume surface gaps survived the competitive-density filter because the categories were too crowded for the brand's content investment level to plausibly lead in 12 weeks. This is the value of the rubric: it stops you from investing in fights you can't win.
Step 3 — The content brief shape
A content brief that turns a measurement gap into a publishable page has six components. Skip any of them and the page either won't surface or won't lead when it does.
1. Target query phrasing — the literal string from the Brand Radar cell. Not a "topic"; the actual query the AI engine returned the gap on. If the cell was "best knowledge base for solo developer using AI coding agents," that exact phrasing belongs in the H1 (lightly tightened — "the best knowledge base for solo developers using AI coding agents") and the first paragraph definitional sentence.
2. Target JTBD framing — pulled from the raw capture. What was the underlying job the AI engine assumed the asker was trying to accomplish? The H2 structure mirrors the JTBD; the body delivers on it.
3. Named competitor comparison — at least one section that explicitly compares your brand to the named competitor(s) the cell surfaced at higher positions. Comparison sections with named brand mentions are what the AI engine pattern-matches against on subsequent dispatches.
4. Structured-data markup — minimum FAQPage; HowTo if the JTBD is procedural; Product + Review if comparable products are named. The single biggest mechanical lever on AIO and Gemini surface rate.
5. Internal link upstream — link to the pillar page for the broader topic + at least one other spoke in the same cluster. The internal-link graph is how AI engines establish topical authority on a domain.
6. CTA stack at the bottom — primary CTA to /signup or product page; secondary to related guides; tertiary to a glossary entry that defines the central term. The CTA stack is also content for the AI engine — well-organized "what next" sections are signals of comprehensive coverage.
A brief that captures these six in a 1-page document gives the writer (whether human or LLM-assisted) everything needed to produce a page that closes the gap.
Step 4 — Publication cadence and weekly BR runs
The standard cadence: publish one new page per week against one gap. Re-run Brand Radar at the same time every week. Compare the delta per platform on the cells that targeted each newly-shipped page.
This is the discipline that produces clean attribution. If you publish three pages in a week and BR moves on six cells, you can't attribute the movement; if you publish one page in a week and BR moves on the two cells that page targeted, the attribution is mechanical.
A 12-week roadmap that ships 10 pages (with 2 buffer weeks for editing/iterating) is the right floor. Anything more aggressive and the attribution gets noisy; anything less aggressive and the cumulative surface lift compounds too slowly to justify the measurement instrument.
Step 5 — The measurement loop
Week 11 of the 12-week loop is the measurement readout. For each shipped page, score:
- Did the target cells move? Compare baseline (week 0) to current (week 11) surface rate + top-recommended rate on the specific cells the page targeted.
- Did the target platform move? If the page was prioritized for AIO + Gemini, those are the platforms whose deltas matter. Movement on ChatGPT is incidental.
- Did the wrong cells move? Sometimes a page lifts cells it didn't target. This is informational, not noise — it tells you the page's topical reach is broader than the brief assumed.
- Did the wrong platforms move? If a page prioritized for Claude moved AIO and didn't move Claude, the mechanism assumption was wrong. The page may still be valuable; the prioritization was off.
A worked example from a recent roadmap (anonymized): we shipped a structured-comparison page targeting a 3-cell gap on Perplexity + Claude. After 8 weeks the page lifted those 3 cells from 0% surface to 67% on Perplexity (2/3 cells now surfacing) and 33% on Claude (1/3). A secondary effect: 4 other cells on adjacent JTBDs lifted as well, on ChatGPT (not Perplexity, not Claude). The first effect was the brief's prediction; the second effect was a topical-authority side-benefit. The roadmap was updated to invest the next page in the adjacent JTBD that produced the side-benefit — a different content brief than the original 12-week plan called for.
This is the loop in operation. The roadmap is not static; each weekly run is a chance to adjust based on what actually moved.
When the loop doesn't work
The 12-week loop assumes a brand with at least minimum category presence (some surface rate on at least some queries, some first-party content, some structured-data markup). Brands that fall below that floor — net-new domains, fresh re-brands, brands with no content beyond a homepage — won't see meaningful movement in 12 weeks because the underlying indices haven't established topical authority on the domain yet. For those brands, the 12-week loop is the wrong instrument; what works instead is a 24-week foundational-content build (15-20 pillar pages, 30-40 spokes, schema markup across everything) followed by the standard 12-week optimization loop starting in month 7.
Brand Radar's baseline scoring catches this. If the baseline run shows surface rates under 15% across all 5 platforms on standard category queries, the recommended next action is the foundational build, not the optimization loop. The dashboard surfaces this distinction directly.
How the cluster fits together
The five-spoke Brand Radar cluster on this site is sequenced to read in order:
- How Brand Radar measures AI search visibility — the measurement instrument
- Citation rate vs share of voice — what the headline metrics mean
- Tracking brand mentions across 5 AI platforms — per-platform behavior
- Brand Radar for Indian D2C — India-specific application
- This guide — the conversion from measurement to roadmap
The first four explain what to measure and how. This guide explains what to do with the measurements. Read in order if you're new to the methodology; jump to this one directly if you're already running BR and want the roadmap playbook.
Frequently asked
How many pages should I ship in 12 weeks? 8-10. More than that produces attribution noise; fewer than that compounds too slowly. The constraint is usually not page production capacity but quality at the brief stage — a thin brief produces a page that doesn't close the gap, which wastes the week's slot. Spend more time on briefs than on writing.
What if the same gap shows up on multiple platforms? That's the easiest case. A single well-built page can close a cross-platform gap if it matches the JTBD phrasing the cells share. The Brand Radar dashboard groups cells by query string so you can see the cross-platform aggregation directly. If 4 of 5 platforms have a gap on the same query, that gap is one investment — not four.
Should I trust an LLM-assisted draft, or write the page myself? LLM-assisted drafting works well for the body of a page once the brief is complete. The brief itself — query targeting, JTBD framing, competitor selection, structured-data scope — should be human-driven. The pattern that fails is asking an LLM to "write a page that ranks on [topic]" — too vague to produce a page that closes a specific measurement gap.
How do I know if I should iterate a page or kill it? Score it at week 11. If the target cells moved at all (even partial movement — 1 of 3 cells lifting), iterate the page with a tighter brief. If the target cells didn't move at all in 8+ weeks and a competitor's equivalent page is still cited in the cells, the mechanism assumption was wrong; redirect the page to a different JTBD framing rather than spending another 8 weeks on the same approach.
How does this fit with classic SEO content roadmapping? The two roadmaps overlap on category-pillar work but diverge on AI-search-specific optimization. A pure classic SEO roadmap would emphasize blue-link rank, organic search volume, and SERP position; a GEO roadmap built from Brand Radar emphasizes AI-engine surface rate, competitive density in the answer, and platform-specific gaps. Both matter — the four-index reality means content optimized for AI engines is also content Google's classic ranking algorithm increasingly favors. See AI search vs Google SEO for the comparative.
Ready to build your 12-week roadmap?
→ Start free with one project — baseline Brand Radar dispatch in 90 minutes
→ Read the methodology guide for the underlying measurement instrument
→ See the published Notion audit — what a baseline gap analysis looks like
→ Browse the Brand Radar product page for tier comparison